Companies use data science and analytics to improve their services and products. It makes a lot of sense to measure what users like and only build what people want to use.
But the collected data can be very sensitive and undermine the rights of users if a data loss occurs. Data privacy laws, therefore, dictate appropriate technical and organizational measures to ensure a level of security appropriate to the risk.
Many organizations can’t afford highly restricted environments and are left with either limited data analytics or the risk of a data leak and resulting penalties.
One way to protect data subjects and combine business needs with user rights is anonymization and in this article, we’ll gonna take a look at it.
History
One of the oldest methods of anonymization is the removal (suppression) of direct personal identifiers from the data such as names or phone numbers.
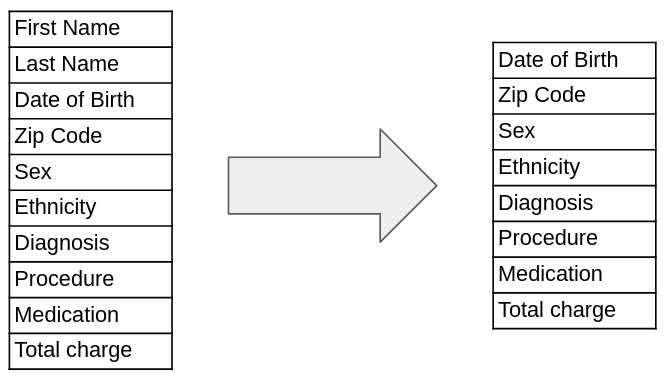
Until 1997, the resulting dataset was considered more or less anonymized and hospitals in the US, for example, released such data to the public.
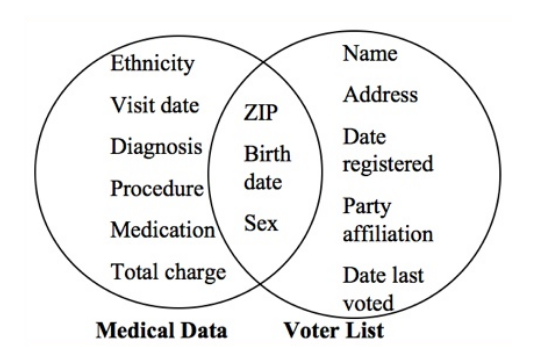
But then Latanya Sweeney entered the stage and conducted a re-identification experiment.
She successfully re-identified individuals by combining public medical records with other accessible records.
The “linkage attack” was born, where adversaries collect information from multiple data sources and then combine that data to re-create personally identifiable information.
Latanya Sweeney conducted more research on re-identification and was met with publication challenges. The fear was that she is publicly exposing a serious issue with no known solution.
In 2017, Forbes named Sweeney one of the most influential women in technology.
The concept of removing names and direct identifiers is considered pseudonymization if at all. Working with this data requires organizations to control the risk of a data breach since disclosure would affect the users rights.
Anonymization
Today, organizations have to provide evidence for anonymization since it exempts the business from strict data-privacy requirements. It has to be clearly documented why data subjects can no longer be identified directly or indirectly from the dataset.
Most successful anonymization efforts involve the application of multiple techniques.
K-Anonymity protection model
The concept of k-anonymity was first introduced by Latanya Sweeney and Pierangela Samarati in a paper published in 1998.
Data is said to have the k-anonymity property if the information for each person contained in the release cannot be distinguished from at least k - 1 individuals whose information also appear in the release.
The more personal attributes in a dataset, the harder it is to accomplish k-anonymity over all the attributes combined. Let’s consider this table of fictitious patient records.
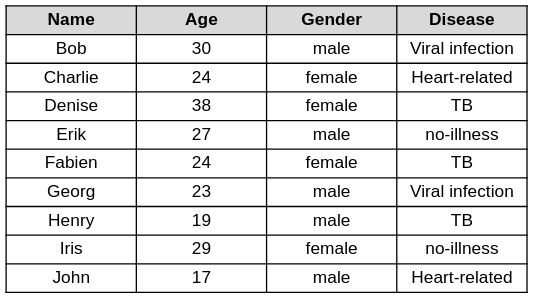
The two common methods to support k-anonymity are:
Suppression means that the values of attributes are replaced by a wildcard.
Generalization describes the replacement of individual values of attributes to a broader category.
In the following table we accomplished a 2-anonymity with respect to ‘Age’ and “Gender’ since for any combination of these attributes there are always at least 2 rows with the same value.
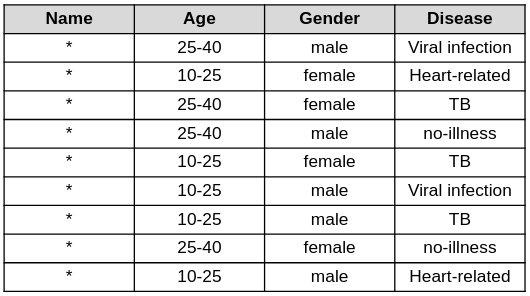
The attributes ‘Age’ and ‘Gender’ are quasi-identifiers and when combined, can support re-identification to yield personally-identifying information. Each tuple of quasi-identifiers has to occur at least in k records of a dataset to accomplish k-anonymity.
K-anonymity is a promising approach for group-based anonymization given its simplicity, it is however susceptible to attacks. When background knowledge is available an attacker can use it to re-identify people. In the above example, background knowledge about the disease can support an attack on the anonymity of individuals.
Given the existence of such attacks where sensitive attributes may be inferred from k-anonymity data, the following methods have been created to further k-anonymity by additionally maintaining the diversity and closeness of sensitive fields.
The l-diversity Principle An equivalence class is said to have l-diversity if there are at least l “well-represented” values for the sensitive attribute. A table is said to have l-diversity if every equivalence class of the table has l-diversity.
The t-closeness Principle An equivalence class is said to have t-closeness if the distance between the distribution of a sensitive attribute in this class and the distribution of the attribute in the whole table is no more than a threshold t. A table is said to have t-closeness if all equivalence classes have t-closeness.
Differential Privacy
This technique was developed by cryptographers and draws much of its language from cryptography. Simply put differential privacy introduces two methods to balance data usefulness and privacy protection.
First, an algorithm injects random noise into a data set to protect the privacy of an individual. The noise is small enough to enable analysts and researchers to provide useful insights.
Secondly, the amount of information revealed is calculated and deducted from a so-called privacy-loss budget. The reference book for differential privacy is “The Algorithmic Foundations of Differential Privacy” by Aaron Roth.
Apple has released a whitepaper describing local differential privacy. The interesting twist here is that the noise is added on the users’ smartphone even before the data is sent to the Apple backend servers.
An interesting approach we have been discussing in the posting System Architecture - Shift To The Client.
Recap
The challenge of privacy-preserving data analysis has a long history. As data about individuals is more detailed than ever, the need for a robust approach to data anonymization is no longer optional.
The clever matching of different data collections and resulting de-anonymization threatens any approach. Organizations have to innovate and underline how they handle the obtained user data responsibly.